

Feche os olhos e viaje conosco para Roma, Londres, Paris, Zurique, Lyon ou Mérida – uma cidade de origem romana, repleta de edifícios, antigas ruínas e muita história. Você está andando por uma rua estreita quando, de repente, dá de cara com uma placa de mármore coberta de texto.
Em nosso exercício de imaginação, somos capazes de ler aquela inscrição em latim de centenas de anos – que maravilha! Só que há um pequeno problema: a placa está quebrada e mostra apenas umas poucas letras, o que impede sua compreensão. Sem a mensagem, seria o fim da viagem?
No que depender das tecnologias mais recentes, não! Nesta edição de #FuturoPresente, vamos falar do Aeneas (Eneias): o primeiro modelo de Inteligência Artificial (IA), desenvolvido pelo Google em parceria com universidades europeias, capaz de “ler” as partes desaparecidas de antigas inscrições.
“Mas, como isso é possível? É leitura mesmo ou é ‘chute’?”, você pode perguntar. Então, venha conosco para descobrir como funciona o Aeneas e conhecer os limites desta tecnologia que promete revelar literalmente o “invisível” com o uso de matemática, estatística e acesso a documentos antigos e bancos de informações. A viagem de verdade começa agora!
Um antigo sonho prestes a ser realizado?
O primeiro sistema de escrita nasceu há cerca de 5.300 anos na Mesopotâmia, entre os sumérios. Nos séculos seguintes surgiram outros sistemas no Egito, China, Grécia e entre as antigas culturas mesoamericanas. Com o uso de um código que podia ser ensinado e replicado, essas civilizações conseguiam estruturar a economia, a administração pública, a justiça, a religião e até uma ciência empírica; também contavam histórias e registravam sua visão de mundo, sonhos, receios e esperanças.
Um processo que seguiu pelos milênios e chegou até nós trazendo consigo a filosofia, o direito, a ciência e a tecnologia. Nessa larga jornada, muitos documentos se perderam totalmente, consumidos pelo próprio tempo ou, então, intencionalmente destruídos, como nos incêndios e autos de fé que, ao longo da História, marcaram momentos ruins da humanidade.
Muitos escritos, porém, sobreviveram, e outros tantos permaneceram entre nós, mas com lacunas – uma página faltando aqui, um buraco no papiro ali, uma parte da lousa de pedra ou cerâmica que sumiu. E são justamente esses documentos – que podem enriquecer muito a nossa compreensão do passado –, o objeto de interesse do Aeneas.

Antes de seguir em frente…
Vale observar que, ao menos neste momento, o Aeneas trabalha exclusivamente com inscrições latinas. Seu nome, aliás, sinaliza isso: Aeneas é Eneias, herói troiano derrotado por Aquiles na Guerra de Troia que é apresentado na “Eneida”, de Virgílio, como ancestral de Rômulo e Remo, os fundadores de Roma. Além disso, o Google oferece um segundo modelo, batizado como “Ithaca” (Ítaca, terra natal de Ulisses, herói grego da “Ilíada” e da “Odisseia”), para a leitura de textos em grego.
Por que esses dois idiomas e não o chinês, por exemplo? A escolha se justifica porque ambos os sistemas de escrita deixaram uma quantidade impressionante de documentos em papiro, pergaminho e pedra – apenas para se ter uma ideia, a cada ano, em média, são descobertas cerca de 1.500 inscrições latinas nos antigos territórios do Império Romano!
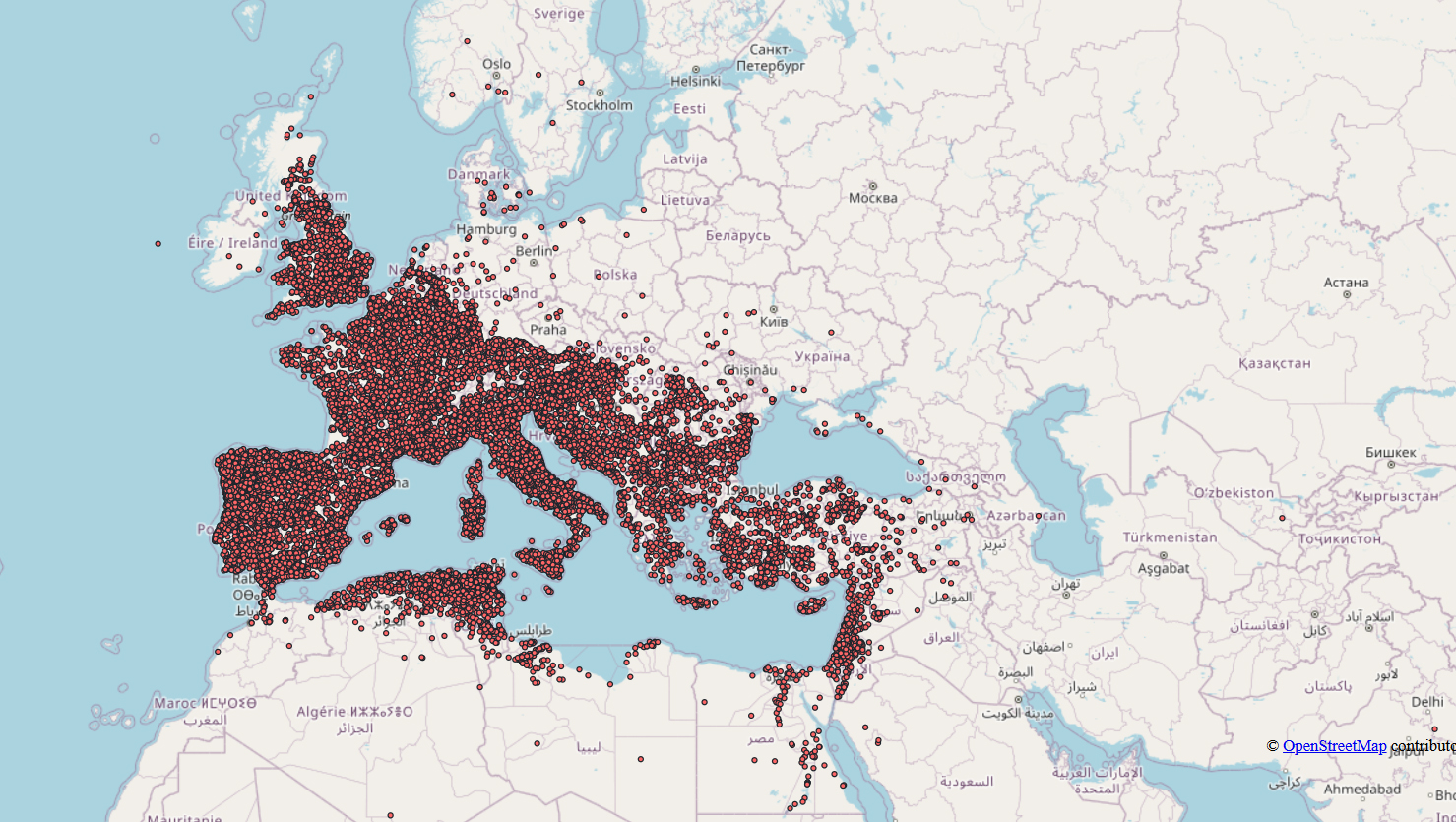
Esses textos, especialmente nos últimos trezentos anos, vêm sendo cuidadosamente estudados e catalogados, gerando dados de pesquisa muito sólidos. Esses dados, por sua vez, funcionam como “norteadores” da IA, uma vez que é a partir deles que ela vai construir suas próprias conclusões.
No futuro, nada impede que outras civilizações que também deixaram vastos acervos escritos, como a chinesa, a egípcia e a babilônica, sejam incorporadas ao Aeneas ou, então, virem objeto de modelos de IA específicos. Seria algo espetacular!
Buscando “match” nos bancos de dados
A “magia” do processo pode ser resumida em um termo que aparece logo na abertura do texto de apresentação do Google para o Aeneas: contextualização. A palavra contextualizar vem do verbo latino “contexere”, que significa entrançar, tecer junto ou conectar.
No caso da ferramenta de IA, ela se associa a aproximar e buscar pontos de conexão entre a peça examinada – a imagem de um fragmento de lousa tumular, por exemplo – e milhares de documentos associados à civilização romana.
Entre os pontos de conexão estão as palavras escolhidas, a forma de organização das palavras nas frases (sintaxe) e a proximidade geográfica e cronológica entre o texto investigado e os textos de referência.

Em ombros de gigantes
A bem da verdade, esse processo não é novo: ele é usado desde o século XVIII por epigrafistas – especialistas em escritas antigas – para supor com maior precisão quais seriam os textos faltantes e também elementos como a origem geográfica e cronológica de um dado documento.
Acontece, porém, que esse método, para ser realmente científico, demanda muito conhecimento e uma quantidade enorme de contextualizações – consulta a textos semelhantes, consideração de aspectos específicos da escrita na época e na região do achado etc. Um trabalho gigantesco que acaba revelando informações importantes, porém sempre em pequenas quantidades e com a possibilidade (ainda que remota) de erros.
Uma super-contextualização
E é aí que reside o diferencial do Aeneas: com os recursos de uma IA especificamente treinada para a epigrafia e com acesso a bancos de dados altamente especializados, os resultados vêm à tona em uma velocidade infinitamente maior e, em muitos casos, com ainda mais precisão.
Uma super-contextualização, enfim, que caminha para a perfeição quando o próprio epigrafista calibra os parâmetros de pesquisa da ferramenta e examina os resultados finais propostos pela máquina.
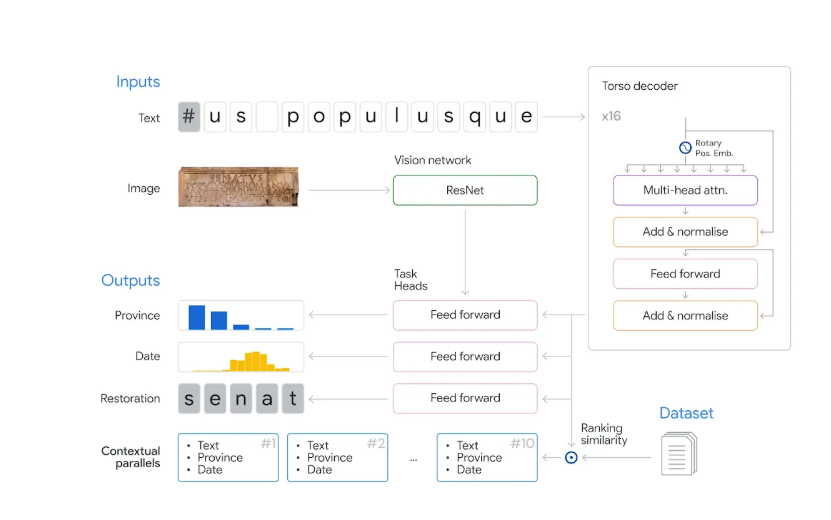
Organizando as letras
Se, por um lado, o Aeneas nasceu com a força da matemática aplicada às ferramentas de IA do Google, por outro ele só é possível graças à digitalização de bancos de dados construídos ao longo de décadas por pesquisadores humanos, como as bases de dados de pesquisadores de Roma, Heidelberg, Ingolstadt (Alemanha) e Zurique.
Esses dados foram compilados, organizados e normatizados para gerar um super-banco denominado Latin Epigraphic Dataset (LED), que reúne nada menos do que 176 mil inscrições coletadas por arqueólogos e epigrafistas em várias partes do antigo Império Romano. Essas inscrições e outras, incorporadas quase que diariamente, formam os “fios” da contextualização da máquina (tipo de documento; formato do texto; época da inscrição; local da inscrição; etc.).
Na província certa, no tempo certo!
Ao examinar inscrições danificadas, o Eneias é capaz de restaurar trechos perdidos de até dez caracteres com uma precisão de 73%, considerada muito alta. Essa precisão cai para 58% quando o número de caracteres perdidos é maior, um percentual ainda visto como excepcional pelos pesquisadores. Lembrando que, em um estudo como esse, uma única palavra recuperada pode ser uma chave que leva a outras descobertas!
Além de “reviver” as palavras, o modelo apresenta os caminhos que o levaram à sua conclusão. E, quando alimentado com dados visuais – uma foto da epígrafe em estudo – é capaz de atribuir sua localização em uma das 62 províncias romanas com uma precisão de 72% (lembrando que, em seu período de máxima expansão, o Império Romano chegou a ter cinco milhões de quilômetros quadrados, uma área maior que a da Comunidade Europeia). Quanto à datação de um texto, a margem de erro é de apenas 13 anos, considerada excelente para uma civilização que chegou a mais de mil e quinhentos anos.
Validando o “Divino Augusto”
O Aeneas foi colocado à prova ao analisar um texto famoso e muito conhecido dos epigrafistas, arqueólogos e historiadores: o “Res Gestae Divi Augusti” – “Os Atos do Divino Augusto”, registro em primeira pessoa feita pelo primeiro imperador romano, Augusto (63 a.C. – 19 d.C.), do qual restam vários fragmentos gravados em pedra distribuídos por várias regiões.

Convidado a datar esses registros com base nos mecanismos de contextualização, o modelo de IA os situou entre o final do primeiro século a.C. e os primeiros anos da Era Cristã – e, de quebra, apontou diferenças na grafia dos fragmentos. Ao chegar a essa conclusão, validou e foi validado pelas conclusões dos melhores pesquisadores do campo!
Outro exemplo: ao analisar sem dados prévios o texto do chamado “Altar Votivo de Mogúncia”, monumento localizado em Mainz, na Alemanha, o Aeneas sugeriu uma data para a inscrição – o ano de 211 d.C., que bate totalmente com a datação oficial. Além disso, também identificou conexões linguísticas com outras epígrafes encontradas na mesma região, o que permitiu que o sistema também localizasse a inscrição no espaço geográfico com total precisão.
Conclusão: expansões, limites e outras possibilidades
Podemos afirmar que o sucesso de modelos de IA como o Aeneas parte de uma grande premissa: a da colaboração entre os pesquisadores. É ela que alimenta o sistema de informações e que, na interação constante com a máquina, possibilita o aprendizado, a construção de vieses e o refinamento das respostas.
A mesma colaboração que está fazendo com que seja possível pensar na expansão do Aeneas para suportes recentes da escrita latina, como pergaminhos medievais, peças religiosas e obras de arte. E, é claro, em outros modelos capazes de oferecer serviços semelhantes em relação a epígrafes chinesas, egípcias, etruscas, babilônicas e maias, por exemplo.
Em relação aos limites, eles são os aplicáveis às ferramentas atuais de IA: elas requerem, acima de tudo, validação humana, e não devem ter suas conclusões tomadas como a “resposta exata absoluta”. Como ferramentas auxiliares de pesquisadores humanos, esses modelos prometem ampliar e enriquecer muito as possibilidades de trabalho.
Em síntese: conectando um passado remoto e um presente futurista, estamos mais perto da leitura das “inscrições invisíveis” – isto é extraordinário!
P.S.: Há algum tempo, dentro da série #FuturoPresente, publicamos um artigo que tratou do “Desafio do Vesúvio” (“Vesuvius Challenge”), competição criada para desafiar pesquisadores a acessarem os conteúdos dos frágeis papiros carbonizados encontrados em Herculano (cidade destruída durante a erupção do Vesúvio no ano de 79 d.C.), usando ferramentas de tomografia digital e de IA. Os resultados são excepcionais! Assim, vale a pena conferir!
Para ir mais longe – links interessantes:
“Aeneas transforms how historians connect the past” (“Aeneas transforma a forma como os historiadores se conectam ao passado”) – Google. Em inglês.
“Contextualizing ancient texts with generative neural networks” (“Contextualizando antigos textos com redes neurais generativas”) – Revista “Nature”. Em inglês.